There are many ways to download files from an S3 Bucket, but if you are downloading an entire S3 Bucket then I would recommend using AWS CLI and running the command aws s3 sync s3://SOURCE_BUCKET LOCAL_DESTINATION.
In the examples below, I’m going to download the contents of my S3 Bucket named radishlogic-bucket.
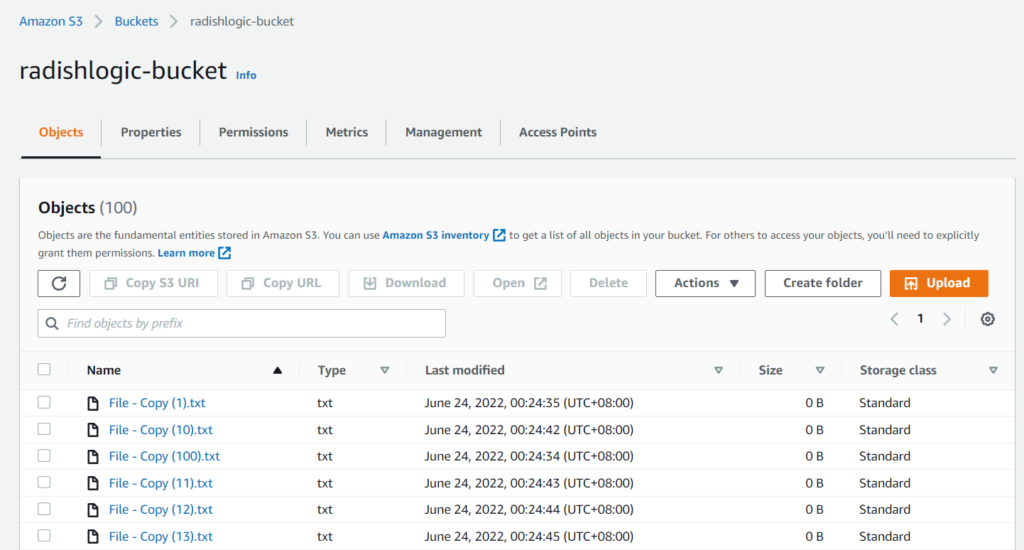
- Example 1: Download S3 Bucket to Current Local Folder
- Example 2: Download S3 Bucket to a Different Local Folder
- sync vs cp command of AWS CLI S3
- Increasing S3 Download Performance
- Limiting the Bandwidth when Downloading an S3 Bucket
Example 1: Download S3 Bucket to Current Local Folder
If you want to download the whole S3 Bucket in the same folder that you are in, then you should use the command aws s3 sync s3://SOURCE_BUCKET ..
In our example S3 Bucket above, the AWS CLI will be like this.
aws s3 sync s3://radishlogic-bucket .Notice that the LOCAL_DESTINATION is set to a dot (.). This means that you are downloading to the current folder that you are in.
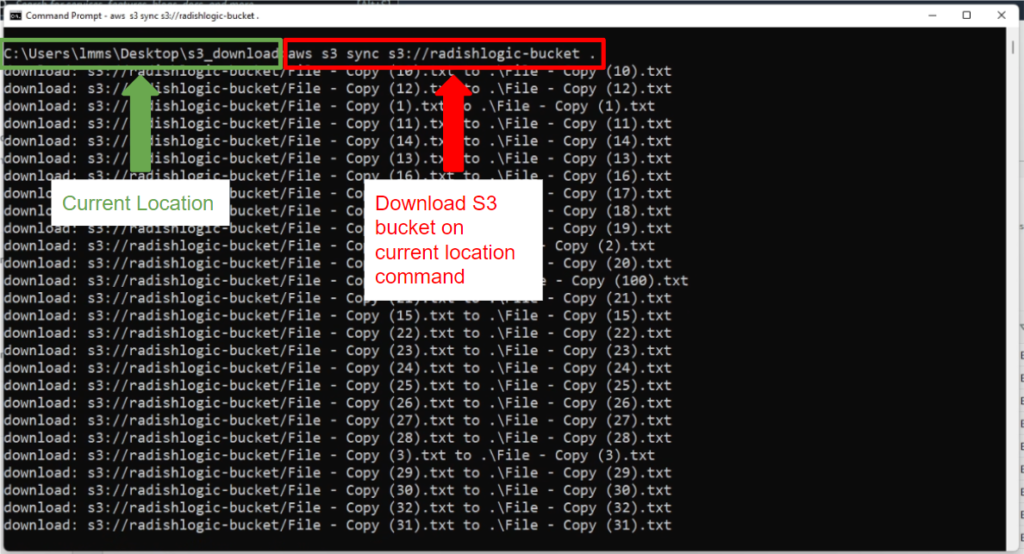
In the screenshot above, I am downloading the S3 Bucket named radishlogic-bucket. In my Windows command prompt, I am in C:\Users\lmms\Desktop\s3_download folder and I want to download the S3 Bucket in the same folder. To start the download process, I will run the command above.
If you are using the AWS CLI command in Mac or Linux, it will be the same command.
Example 2: Download S3 Bucket to a Different Local Folder
If you want to download the S3 Bucket to a different folder using AWS CLI, then you can point the LOCAL_DESTINATION to that folder.
There are 2 ways to do this – via absolute path and relative path.
An absolute path is where you specified the exact path from the root volume where the destination folder is. Below is an example of downloading an S3 Bucket using absolute path.
aws s3 sync s3://radishlogic-bucket C:\Users\lmms\Desktop\s3_download\A relative path is where you specify the path to the target folder from the current folder that you are in.
aws s3 sync s3://radishlogic-bucket .\Desktop\s3_download\Note: Absolute and relative path for aws s3 sync is also possible for Mac or Linux.
sync vs cp command of AWS CLI S3
There are 2 commands that you can use to download an entire S3 bucket – cp and sync.
aws s3 cp copies the files in the s3 bucket regardless if the file already exists in your destination folder or not. If the file exists it overwrites them.
aws s3 sync first checks if the files exist in the destination folder, if it does not exist or is not updated then it downloads the file.
For downloading whole s3 buckets I recommend aws s3 sync because if you suddenly lost your internet connection, you will not have to download the whole s3 bucket, but it will continue where it left off.
Actually, what I do is write a script that does aws s3 sync multiple times just to be sure I have downloaded the s3 bucket even if I have intermittent internet like the ones below.
Shell Script to download the whole S3 Bucket via AWS CLI
#!/bin/sh
aws s3 sync s3://radishlogic-bucket .
sleep 5m
aws s3 sync s3://radishlogic-bucket .
sleep 5m
aws s3 sync s3://radishlogic-bucket .
sleep 5m
aws s3 sync s3://radishlogic-bucket .PowerShell Script to download an entire S3 Bucket via AWS CLI
aws s3 sync s3://radishlogic-bucket .
Start-Sleep -Seconds 300 # Wait for 5 minutes
aws s3 sync s3://radishlogic-bucket .
Start-Sleep -Seconds 300 # Wait for 5 minutes
aws s3 sync s3://radishlogic-bucket .
Start-Sleep -Seconds 300 # Wait for 5 minutes
aws s3 sync s3://radishlogic-bucket .Increasing S3 Download Performance
If you’re downloading a big S3 bucket, you can make the download faster by increasing the number of max_concurrent requests.
Run the command below to increase the max_concurrent_requests to 20.
aws configure set default.s3.max_concurrent_requests 20By default max_concurrent_requests is set to 10 that is why you will notice that aws s3 sync downloads 10 files at a time.
The quickest way to download an S3 bucket is to set the max_concurrent_requests to a number as high as you can. I have actually pushed this to around 200 since my internet and computer can handle it.
Limiting the Bandwidth when Downloading an S3 Bucket
If you want to limit the download speed when copying an entire S3 Bucket to your computer, then this can be done with the command aws configure set default.s3.max_bandwidth 50MB/s.
You can replace the 50MB/s with your target bandwidth. Possible values are in KB/s, MB/s, and GB/s.
This is advantageous if you are not the only one using the internet like in a home or in company networks. Or if you want to browse the internet while downloading the whole S3 Bucket in the background.
Note: As of writing, if you are trying to download the whole S3 Bucket using amazon console, I suggest giving up since it’s not possible. You can only download files one at a time.
I hope the above helps you download a whole S3 bucket via AWS CLI. Let me know your experience in the comments below.
Hello. If the S3 object in the bucket is in the path S3BucketName/Folder1/Folder2/object_file and I sync/copy locally in C:/, will the folder structure of the bucket be copied too? Like C:/Folder1/Folder2/object_file. Or will be the C:/object_file?
Hi Yeni, it will copy the folder structure. 🙂